
6月7日,腾讯混元团队汇聚中山大学、香港科技大学推出全新图生视频模子“Follow-Your-Pose-v2”,只需要输入一张东说念主物图片和一段动作视频,就不错让图片上的东说念主跟班视频上的动作动起来足球投注app,生成视频长度可达 10 秒。

据先容,与此前推出的模子比较,“Follow-Your-Pose-v2”不错在推理耗时更少的情况下,解救多东说念主视频动作生成。此外,模子具备较强的泛化才能,无论输入的东说念主物图片的东说念主物是什么年齿、服装、东说念主种,东说念主物图片的配景何等散乱,动作视频的动作有何等复杂,齐能生成出高质地的视频。
关于使用者来说,“Follow-Your-Pose-v2”让使用者不错用随性一张东说念主物图片和一段动作视频即可生成高质地的视频,不再需要艰苦寻找欢欣高条款的图片和视频,这些相片不错是我方和家东说念主一又友的糊口照,也不错使用是偶像的一张浅易的持拍。
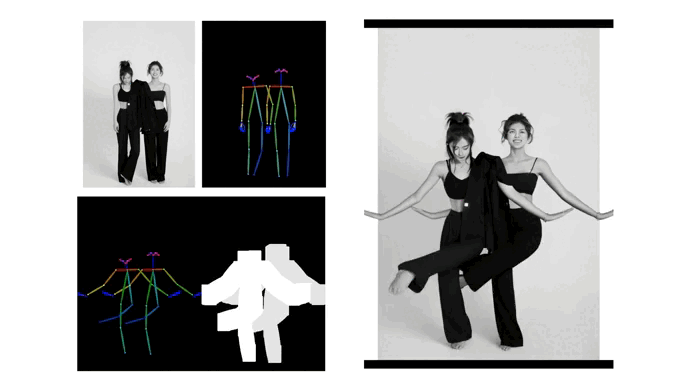
在动作开动图片生成视频的任务中,一般的要领常常需要悉心筛选高质地磨真金不怕火数据,资本高的同期还截止了磨真金不怕火集的鸿沟,从而导致模子在泛化才能的普及上有瓶颈。同期,模子关于图片上蕴含的空间信息的贯穿才能有限,具体表咫尺远景和后景的差异不了了,导致生成视频配景的畸变和东说念主物动作的不准确。

据先容,为了处分这些问题,“Follow-Your-Pose-v2”提议了一个解救随性数目的 “开采器”的框架,通过引入稀奇信息来赋予模子稀奇的才能。其中,该框架中私有的“光流开采器”引入了配景光流信息,赋予了模子在多量有噪声的低质地数据上磨真金不怕火拘谨的才能;该框架中私有的“推理图开采器”引入了图片中的东说念主物空间信息,赋予模子更强的动作跟班才能。
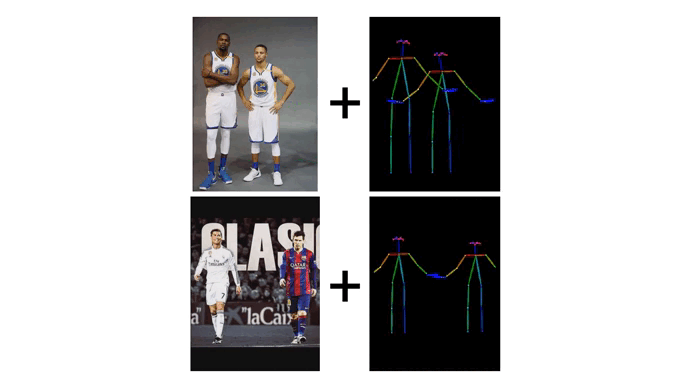
最值得一提的是,“Follow-Your-Pose-v2”还解救单张图片上多个东说念主物的动作开动。模子私有的“深度图开采器”引入了多东说念主物的深度图信息,增强了模子关于多变装的空间位置辩论的贯穿和生成才能。在面临单张图片上多个东说念主物的躯体互相保密问题,“Follow-Your-Pose-v2”能生成出具有正确的前后辩论的保密画面,保证多东说念主“合舞”顺利完成。
在业内东说念主士看来,图像到视频生成的时代在电影骨子制作、增强履行、游戏制作以及告白等多个行业的AIGC欺诈上有着豪迈远景,是本年最热点的AI时代之一。
腾讯混元大模子团队方面暗示,正在继续商议和探索多模态时代。此前,腾讯混元大模子动作时代和解伙伴,解救多家媒体机构制作高质地的主题宣传视频,展示出了较强的骨子贯穿、逻辑推理和画面生成才能。
南边+记者 叶丹